
{kind=link}
{kind=link}
Related news
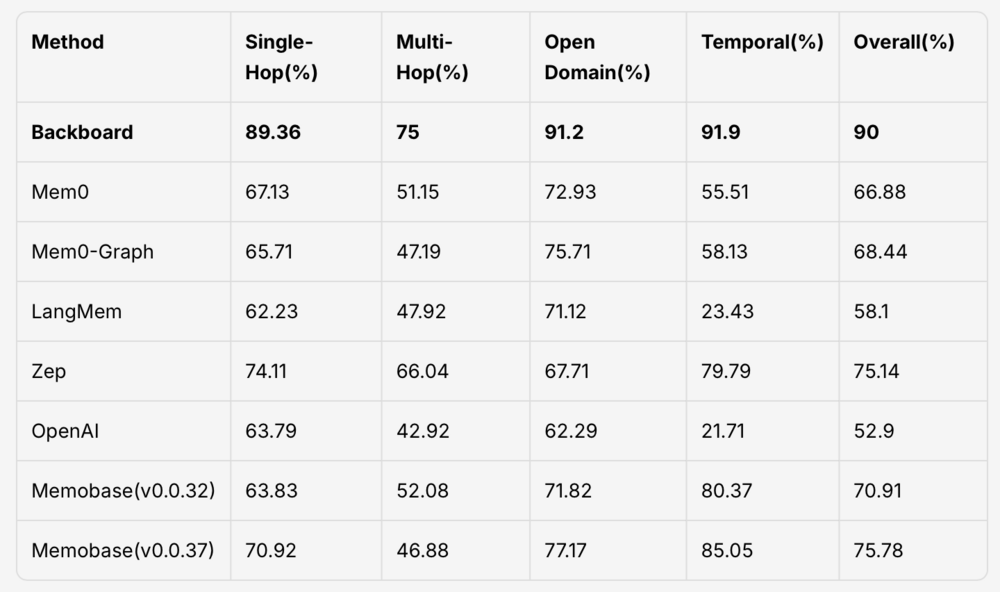
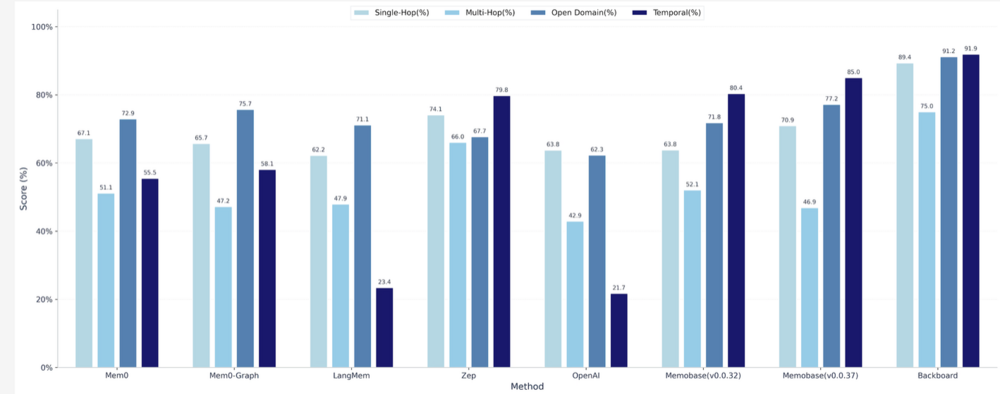
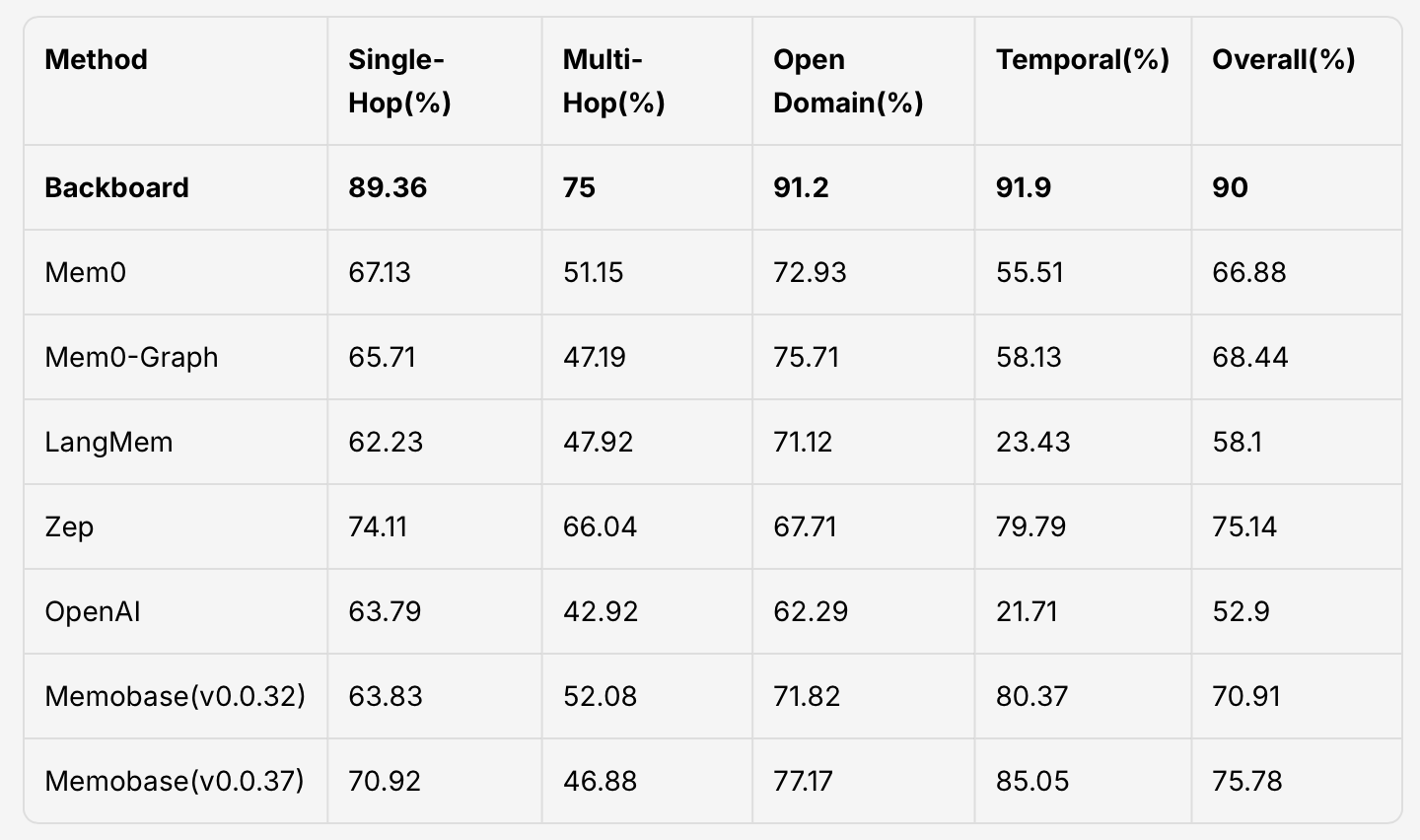
Backboard.io Becomes First AI Platform to Lead Both Major Memory Benchmarks, Accelerating the Era of Agentic AI
Backboard.io is the first AI platform to lead both major memory benchmarks. By making memory foundational and models interchangeable, Backboard enables reliable AI SaaS and agentic systems through ...
Backboard.io and ESPAT.TV Announce Strategic Partnership to Advance AI Infrastructure for Entertainment and Creative ...
Backboard.io, a provider of enterprise-grade AI infrastructure, today announced a strategic partnership with ESPAT.TV, a platform operating at the intersection of entertainment, gaming, creators, a...
Backboard.io Unlocks AI Memory for OpenRouter Users
The ability to add advanced memory and state capabilities to existing integrations directly addresses a major pain point for developers. Our goal is to enable rapid innovation without forcing refac...
AI’s Cost Crisis; Backboard.io Introduces Predictable, Usage-Based Pricing to Tackle Cost Control
By decoupling system costs from model pricing, Backboard exposes and controls the real drivers of AI spend that token-based pricing hides. This shifts AI economics from opaque model bills to observ...
Saas Unicorn Founder Rob Imbeault Returns with Backboard.io the Memory Layer of AI
AI is brilliant, but it forgets. SaaS Unicorn founder Rob Imbeault thinks that’s the biggest problem in the stack. Backed by Mistral, N49P, Garage Capital and DevCap, his new company Backboard is b...